Размер не главное: модель предсказала свойства соединений на "маленьких" данных
Сотрудники межкафедральной лаборатории Интеллектуального химического дизайна химического факультета МГУ использовали технику трансферного машинного обучения, чтобы спрогнозировать свойства молекул исходя из их структуры. Авторы показали, что обучения на нескольких десятках молекул достаточно для получения модели с хорошей предсказательной точностью. Работа опубликована в издании The Journal of Physical Chemistry Letters.
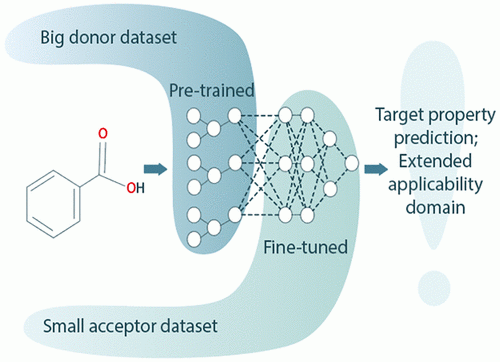
Методы машинного обучения часто используются в химии, чтобы установить зависимость между структурой молекулы и ее свойствами. Для этого анализируется большое количество структур химических соединений и исследуется их физико-химическая и биологическая активность. Результат такого анализа — модель, способная предсказать свойства какого-либо соединения или, наоборот, предложить структуру молекулы с заданными свойствами.
«Этот процесс называется анализом больших данных, поскольку данных на самом деле нужно очень много: несколько тысяч или даже миллионы, — пояснил соавтор работы, заведующий лабораторией химического факультета МГУ, к.х.н. Артем Митрофанов. — Понятно, что в реальности миллион молекул с измеренным в одинаковых условиях свойством найти невозможно. Поэтому химики не могут использовать машинное обучение для решения многих актуальных задач».
Чтобы преодолеть нехватку данных, авторы решили использовать технику трансферного обучения. Ее идея состоит в том, что модель сначала обучается на большом наборе данных, а потом практически полностью переносится и дообучается на маленьких. Причем на первом этапе можно использовать расчетные или не очень точные данные, поскольку предсказательная точность модели уточняется именно вторым маленьким набором данных.
«В качестве первоначального набора данных мы взяли значения коэффициентов липофильности полутора миллионов малых органических молекул, — рассказал Артем Митрофанов. — Этот параметр показывает отношение растворимостей в октаноле и воде и очень удобен в использовании. Его легко посчитать и измерить, поэтому для него существуют большие базы данных».
Как отметил ученый, перенос модели на небольшие данные проходит лучше, если конечное свойство, которое желательно научиться предсказывать, похоже на использованное для обучения. Например, модель на базе коэффициента липофильности предсказывает лучшие результаты для растворимости в воде.
«С помощью предложенного метода нам удалось с хорошей точностью предугадать разнообразные физико-химические и биохимические параметры, — рассказал автор работы, аспирант лаборатории Кирилл Карпов. — Например, температуру кипения, токсичность и активность по отношению к ряду известных мишеней — то, что как раз интересует людей, занимающихся производством лекарственных средств».
В работе авторы выяснили, что всего двадцати молекул с измеренным свойством достаточно, чтобы научиться хорошо предсказывать это свойство.


